protobuf 介绍
ProtoBuf(Protocol Buffers)是一种具有跨平台、语言无关、可扩展等特性的序列化结构数据的方法,可用于网络数据交换及存储。和我们平时使用的 json、xml 是同一种东西。它在解析性能和数据压缩后大小方面比 json、xml 更优秀,目前常用于 rpc。
protobuf 序列化机制
不同于传统的序列化方式,protobuf 在序列化数据之前,需要先定义一个结构体,它是记录数据在序列化和解析时的参照,我们简单看看它的语法:
message Person {
required int32 id = 1;
required string name = 2;
required string hobby = 3;
}
在该结构体的字段定义中,有几个关键位置,分别是类型(如 int32)、字段名(如 name),以及一个编号(如 1、2、3),
使用 protobuf 的双方都需要依照这个结构体定义来进行序列化和解析。
我们通过几个问题来了解其序列化机制吧:
QUESTION1 🙋♂️
在解析序列化数据时,怎么确定当前解析的数据对应哪个字段?在传统的序列化机制中,序列化数据与其对应的字段,都会通过字段名进行联系,但在 protobuf 的序列化结果中,是没有id、name和hobby这样的字段名的,它们会被编号替代。
QUESTION2 🙋♂️
序列化后的字节流,如何分隔各个字段? 我们都知道,数据最终在传输的过程中,是以一个个字节的二进制形式传输的,面对一长串的字节流,如何确定每个字段的字节流段呢?在每个字段的字节流最前面,会有几个特殊字节,称为 Tag,Tag 就充当了边界的作用,分隔各个字段。
如下图,我们可以把字节流看成一个个由 Tag 和数据(value)组成的结构。
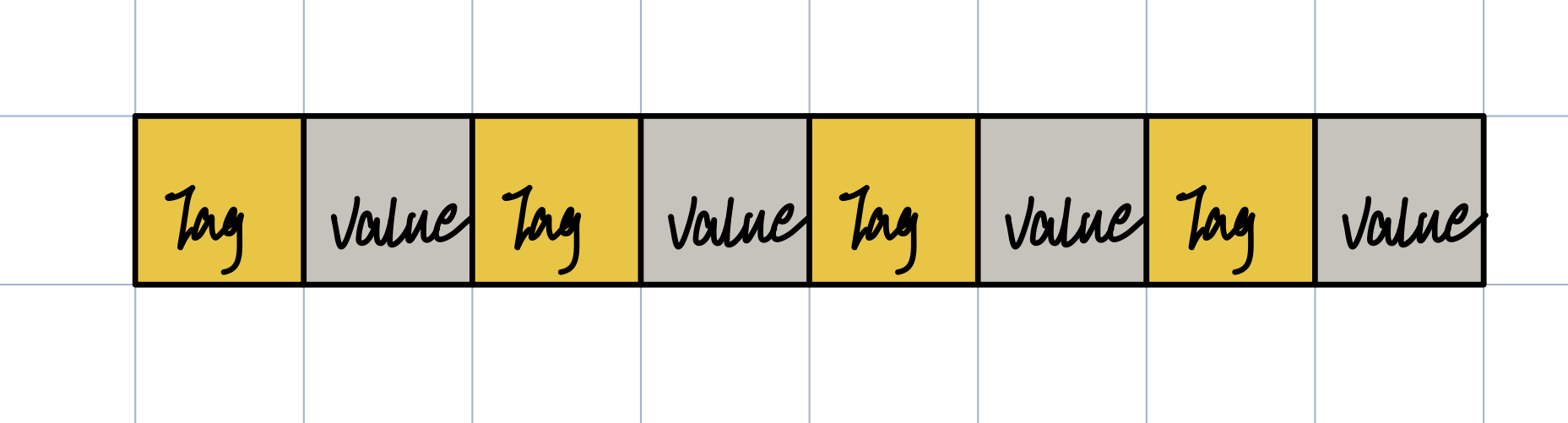
Tag 不仅仅只是起到了分隔字段的作用,它还承载了类型信息,我们来看看 Tag 是如何生成的:
static int makeTag(final int fieldNumber, final int wireType)
{
return (filedNumber << 3) | wireType;
}
其中的fieldNumber,就是我们定义结构体时给的编号,wireType有以下几个值:

wireType总共只有 5 个值,用二进制来表示只需要 3 位,filedNumber << 3把filedNumber左移 3 位,然后与wireType做或运算,wireType即是Tag的最后 3 位。
QUESTION3 🙋♂️
Tag如何保证不和Value混淆?Tag 和Value在字节流中都是一个个字节,如果字节相同,那就会把value误认为 Tag,解析就会出错。
要解决这个问题,我们需要先了解 protobuf 序列化成字节流时的编码方式
可变长度编码(Varint)
我们知道,整数类型的长度都是确定的,如 int 类型的长度为 4 个字节,可表示的整数范围为-231——231-1,但是实际传输中的数字均比较小,会造成字节浪费,可变长度编码就能很好的解决这个问题,可变长度编码规则如下:
- 字节最高位表示数据是否结束,如果最高位为 1,则表示后面的字节也是该数据的一部分
可变长度编码唯一的缺点就是当数很大的时候 int32 需要占用 5 个字节,因为去掉字节最高位后,一个字节能用来表示数据的只剩 7 位,但是从统计学角度来说,一般不会有这么大的数。
上文提到的Tag,还需要 3 位表示数据类型,用来表示编号的位数为 4 位时(能表示 15 个编号),Tag才能用 1 个字节装下。
负数问题
整数在计算机中是以补码形式存储的,-1 的补码形式是1111 1111 1111 1111,这样的值在使用可变长度编码时的效率非常低,所以如果要使用负数强烈不建议使用 int32 和 int64,建议使用 sint32 和 sint64,sint32 和 sint64 会使用 zigZag 编码,生成的数再使用可变长度编码下面介绍一下 zigzag 编码。
zigzag 编码机制如下:
Zigzag(n) = (n << 1) ^ (n >> 31), n 为 sint32 时
Zigzag(n) = (n << 1) ^ (n >> 63), n 为 sint64 时
可以简单理解为:
- 负数: x = 2|x| -1
- 正数: x = 2|x|
下图是一些数按照 zigzag 编码方式后得到的数:

我们把数先经过 zigzag 编码后再进行不定长编码,就能够提高负数在不定长编码中的效率。
定长编码
上文讲到的 Varint 和 zigzag 编码都是针对数字进行编码,在编码字符时使用的是定长编码,定长编码在字节流中的结构是 TLV,即Tag-Length-Value,Length 是一个数字(也会用 Varint 编码),记录的是后面 value 所占的字节数。
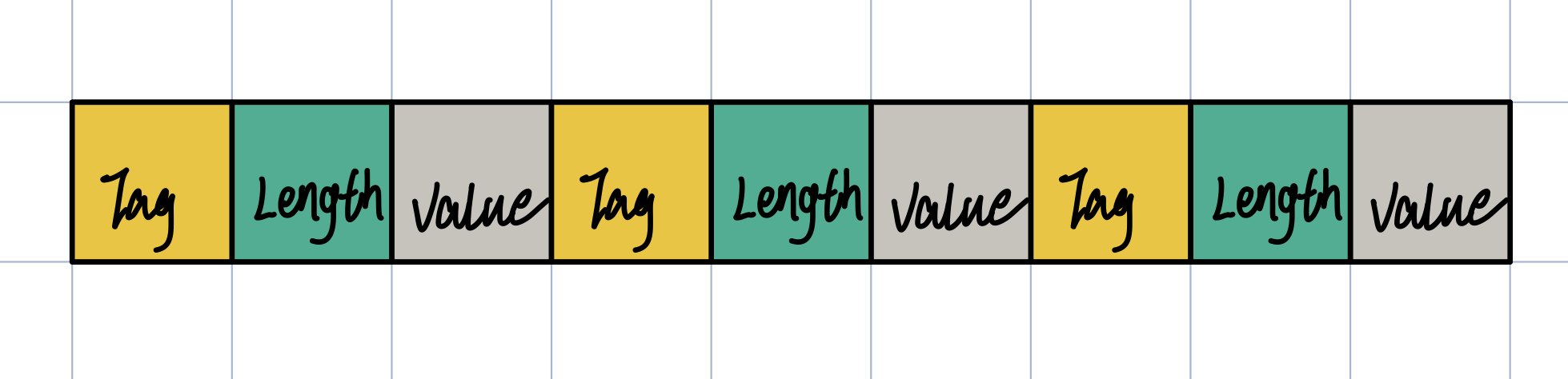
实际的字节流不是只有 TV 或者 TLV,是 TV 和 TLV 混合在一起的。
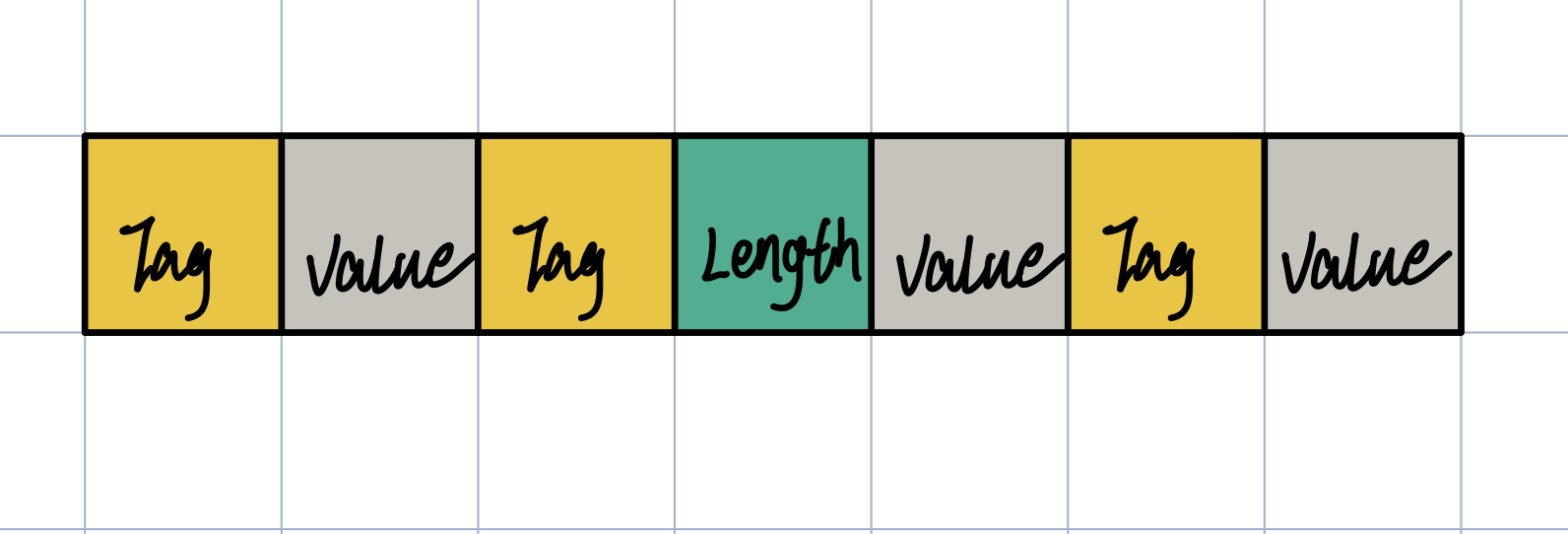
我们现在可以解释为什么不会出现混淆问题了,我们在解析时,首先会取第一个Tag,因为Tag使用了 Varint 编码,根据 Varint 编码规则,如果Tag只有一个字节,那么这个字节的首位会为 0,如果Tag大于 1 个字节,那么继续往后取到首位为 0 的那一个字节,即可正确获取Tag。接着我们通过Tag的二进制后三位可以得到字段的类型wireType,分两种情况:
- 如果类型是数字,那么这是一个 TV 结构,
Value采用不定长编码,我们根据不定长编码规则取得Value后,再往后就是下一个Tag了。 - 如果类型是字符,那么这会是一个 TLV 结构,我们先根据不定长编码规则获取
Length,Length记录了Value的字节数 n,后面的 n 个字节即是Value,再往后就是下一个Tag。
在这个过程中,我们都清楚知道当前的字节是Tag、Length还是Value,不会出现混淆的情况。
为什么 protobuf 的性能更好?
- 没有序列化 key,通过编号代替
- 可变长度编码和 zigzag 编码,减小字节占用